

How To Choose A Machine Learning Algorithm
Do yous know how to cull the correct motorcar learning algorithm among 7 different types?
This is a generic, practical approach that tin be practical to virtually machine learning problems:

This story is composed of vii articles each ane per algorithm, each one have the implementation from scratch, please ensure to follow our newsletter and then you can receive the updates as presently every bit we publish each algorithm from scratch.
1-Categorize the problem
The next step is to categorize the trouble.
Categorize by the input: If it is a labeled information, it's a supervised learning problem. If it'southward unlabeled information with the purpose of finding structure, it's an unsupervised learning trouble. If the solution implies to optimize an objective function past interacting with an environment, it's a reinforcement learning trouble.
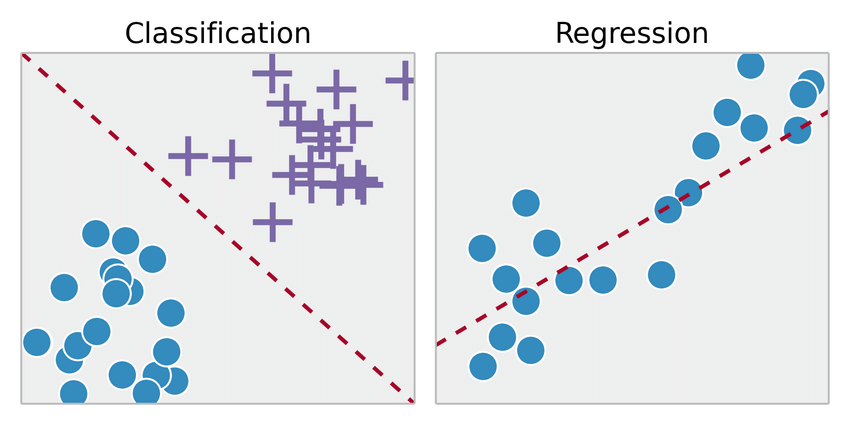
Categorize past output: If the output of the model is a number, it's a regression problem. If the output of the model is a class, it'due south a classification problem. If the output of the model is a gear up of input groups, it'southward a clustering problem.
2-Understand Your Data
Data itself is not the end game, but rather the raw material in the whole analysis process. Successful companies not only capture and take admission to information, only they're also able to derive insights that drive better decisions, which result in amend customer service, competitive differentiation, and higher revenue growth. The process of understanding the data plays a key role in the process of choosing the right algorithm for the correct problem. Some algorithms can piece of work with smaller sample sets while others require tons and tons of samples. Sure algorithms piece of work with categorical data while others similar to work with numerical input.
Analyze the Data
In this step, at that place are two important tasks which are empathise data with descriptive statistics and understand information with visualization and plots.
Procedure the data
The components of information processing include pre-processing, profiling, cleansing, it ofttimes also involves pulling together data from dissimilar internal systems and external sources.
Transform the data
The traditional idea of transforming data from a raw state to a land suitable for modeling is where feature applied science fits in. Transform data and feature applied science may, in fact, exist synonyms. And here is a definition of the latter concept. Characteristic engineering is the process of transforming raw information into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data. By Jason Brownlee.
three-Observe the available algorithms
After categorizing the problem and sympathize the data, the next milestone is identifying the algorithms that are applicative and practical to implement in a reasonable time. Some of the elements affecting the choice of a model are:
- The accuracy of the model.
- The interpretability of the model.
- The complication of the model.
- The scalability of the model.
- How long does information technology take to build, train, and test the model?
- How long does information technology have to make predictions using the model?
- Does the model encounter the business organization goal?
4-Implement automobile learning algorithms.
Fix a machine learning pipeline that compares the performance of each algorithm on the dataset using a set of carefully selected evaluation criteria. Another approach is to use the aforementioned algorithm on different subgroups of datasets. The best solution for this is to do it one time or have a service running that does this in intervals when new information is added.
v-Optimize hyperparameters. In that location are iii options for optimizing hyperparameters, grid search, random search, and Bayesian optimization.
Types of machine learning tasks
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Supervised learning
Supervised learning is and so named considering the human existence acts as a guide to teach the algorithm what conclusions it should come up up with. Supervised learning requires that the algorithm's possible outputs are already known and that the data used to train the algorithm is already labeled with correct answers. If the output is a real number, nosotros call the task regression. If the output is from the limited number of values, where these values are unordered, then it's nomenclature.
Unsupervised learning
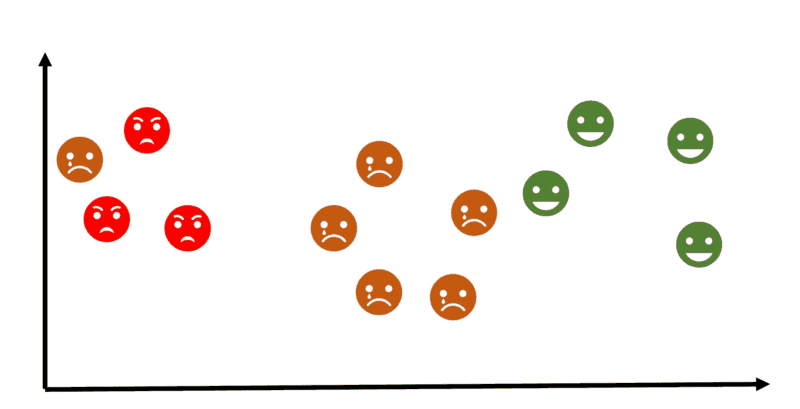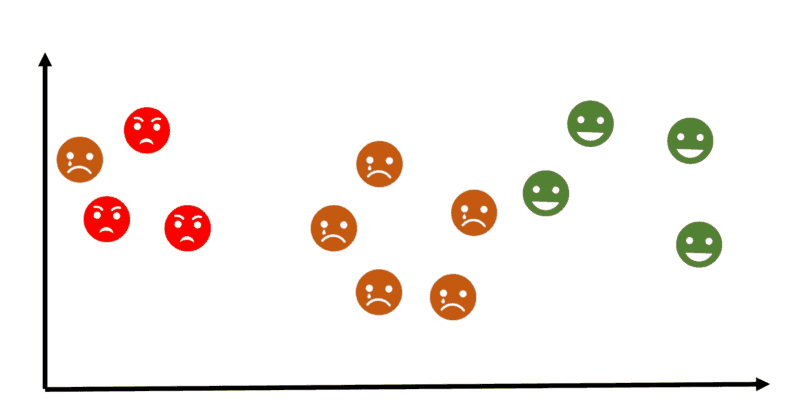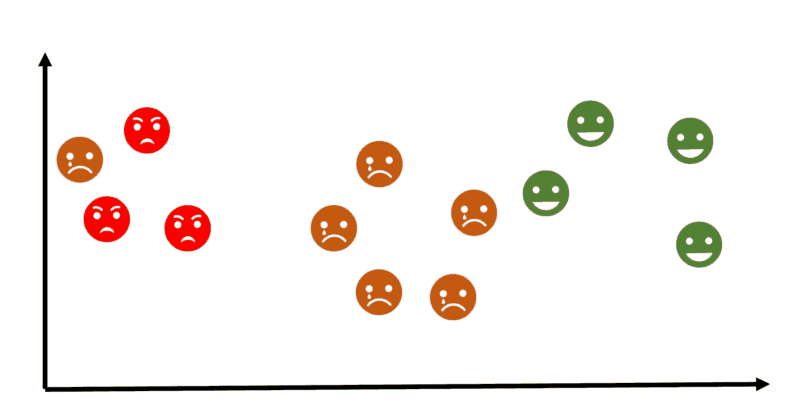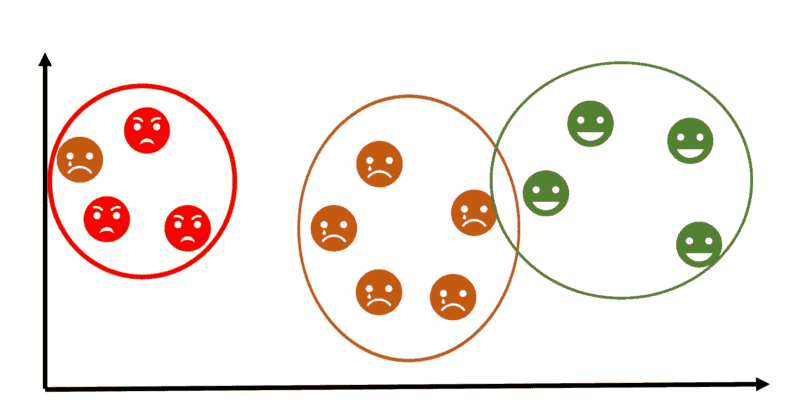
Unsupervised machine learning is more closely aligned with what some phone call true artificial intelligence — the thought that a reckoner can learn to place complex processes and patterns without a human being to provide guidance along the way. At that place is less information about objects, in particular, the train set up is unlabeled. It'south possible to observe some similarities between groups of objects and include them in advisable clusters. Some objects can differ hugely from all clusters, in this way these objects to exist anomalies.
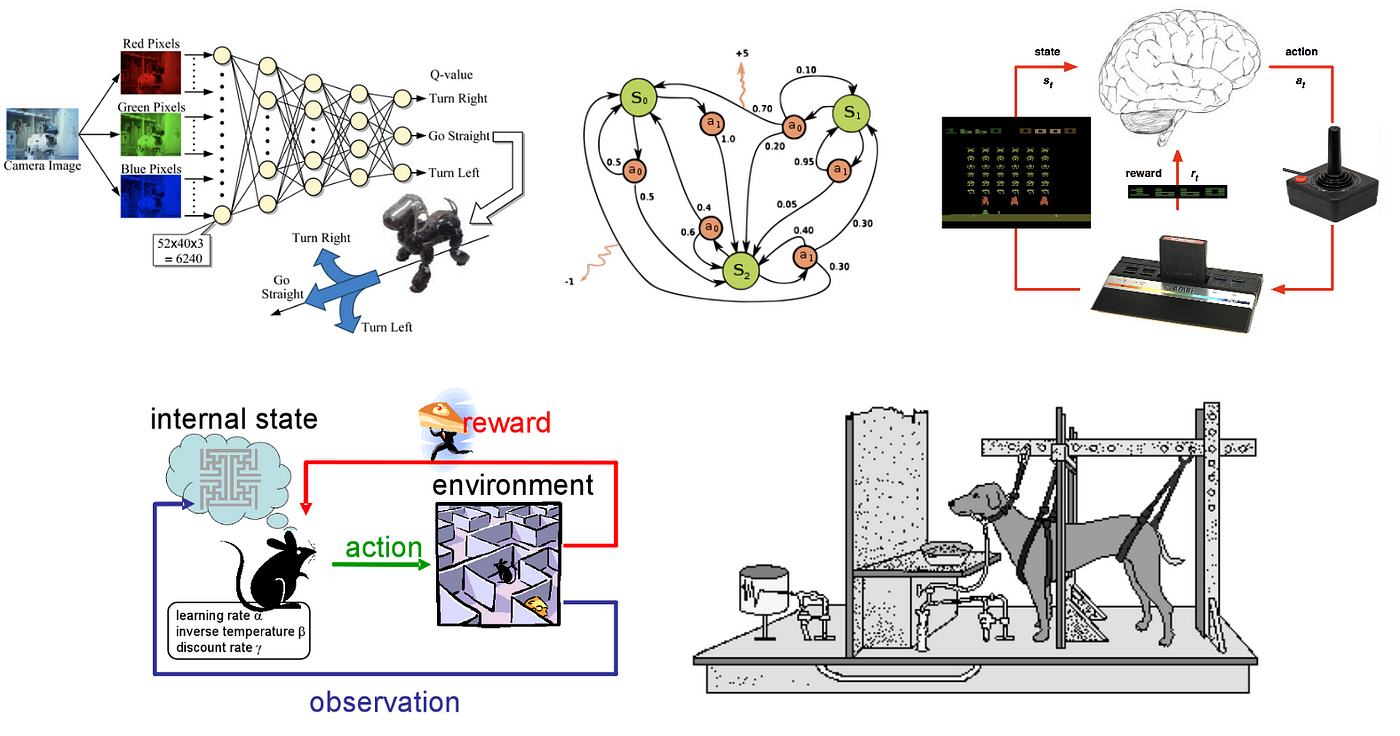
Reinforcement learning
Reinforcement learning refers to goal-oriented algorithms, which learn how to attain a circuitous objective or maximize forth a particular dimension over many steps. For instance, maximize the points won in a game over many moves. It differs from the supervised learning in a way that in supervised learning the training information has the function central with it so the model is trained with the right reply itself whereas in reinforcement learning, in that location is no reply but the reinforcement agent decides what to practice to perform the given task. In the absence of grooming dataset, it is jump to learn from its experience.
Commonly used machine learning algorithms
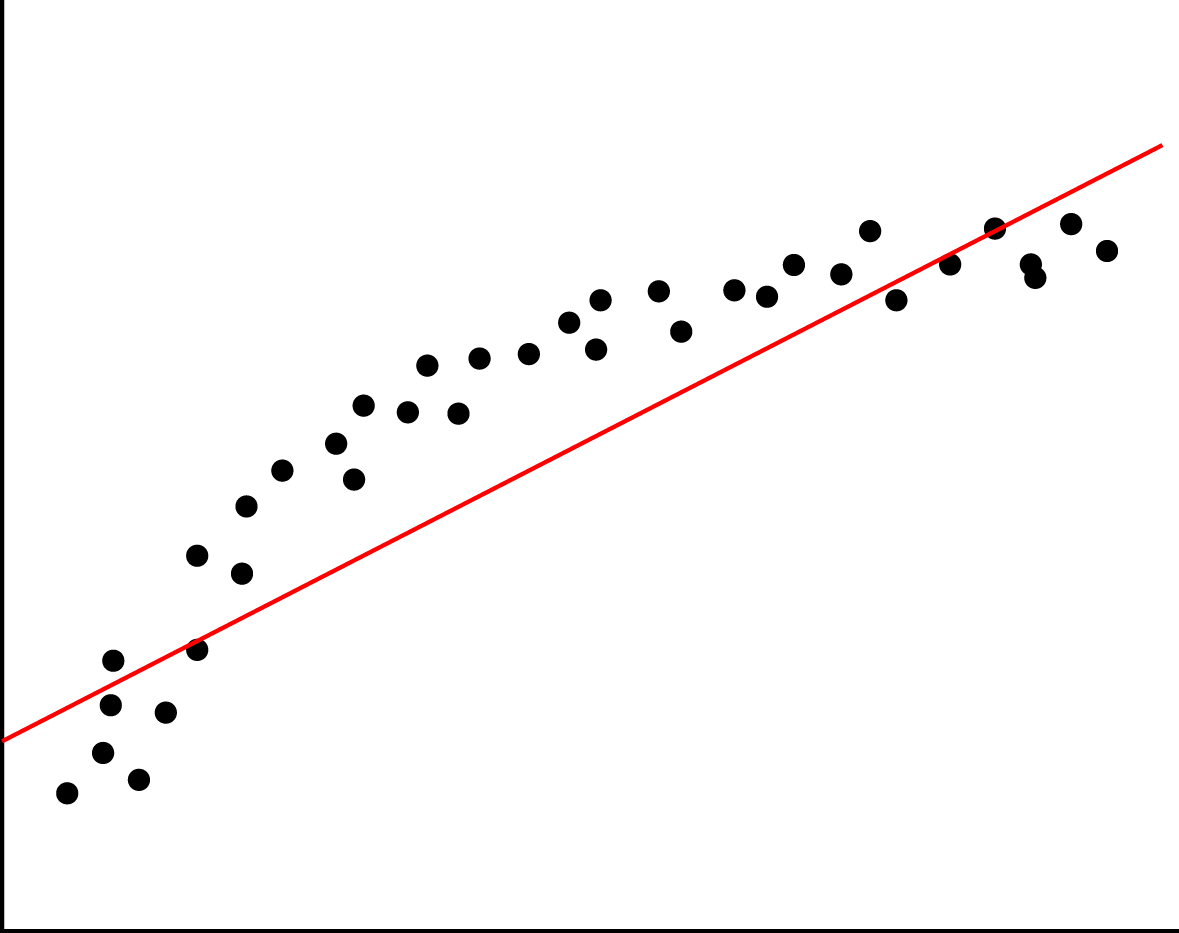
ane-Linear Regression
Linear regression is a statistical method that allows to summarize and study relationships betwixt two continuous (quantitative) variables: One variable, denoted 10, is regarded as the independent variable. The other variable denoted y is regarded equally the dependent variable. Linear regression uses one independent variable X to explicate or predict the outcome of the dependent variable y, while multiple regression uses ii or more than independent variables to predict the outcome according to a loss office such as mean squared error (MSE) or mean absolute mistake (MAE). And so whenever you are told to predict some time to come value of a process which is currently running, you can go with a regression algorithm. Despite the simplicity of this algorithm, information technology works pretty well when in that location are thousands of features, for example, a bag of words or due north-grams in tongue processing. More complex algorithms endure from overfitting many features and not huge datasets, while linear regression provides decent quality. However, is unstable in instance features are redundant.
To see the implementation from scratch checkout our latest story near this topic.
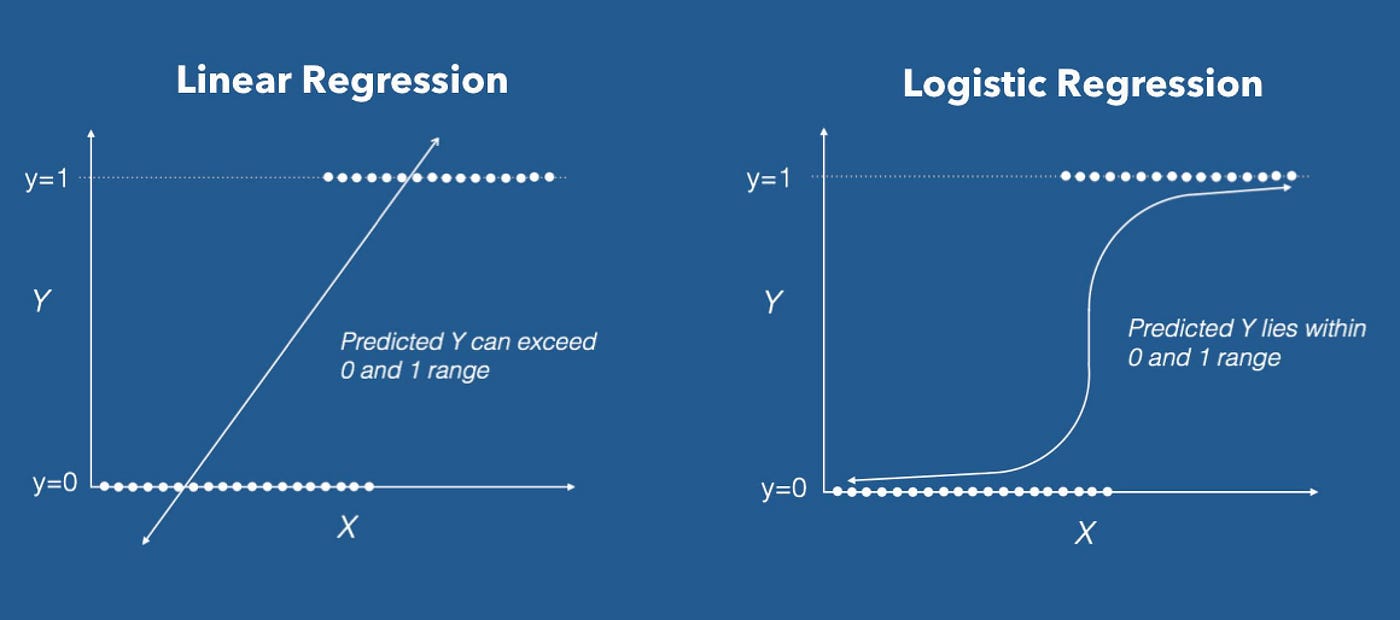
2-Logistic Regression
Don't confuse these classification algorithms with regression methods for using regression in its championship. Logistic regression performs binary classification, and so the label outputs are binary. We tin can also think of logistic regression as a special case of linear regression when the output variable is categorical, where nosotros are using a log of odds every bit the dependent variable. What is awesome about a logistic regression? It takes a linear combination of features and applies a nonlinear part (sigmoid) to it, so it'due south a tiny instance of the neural network!
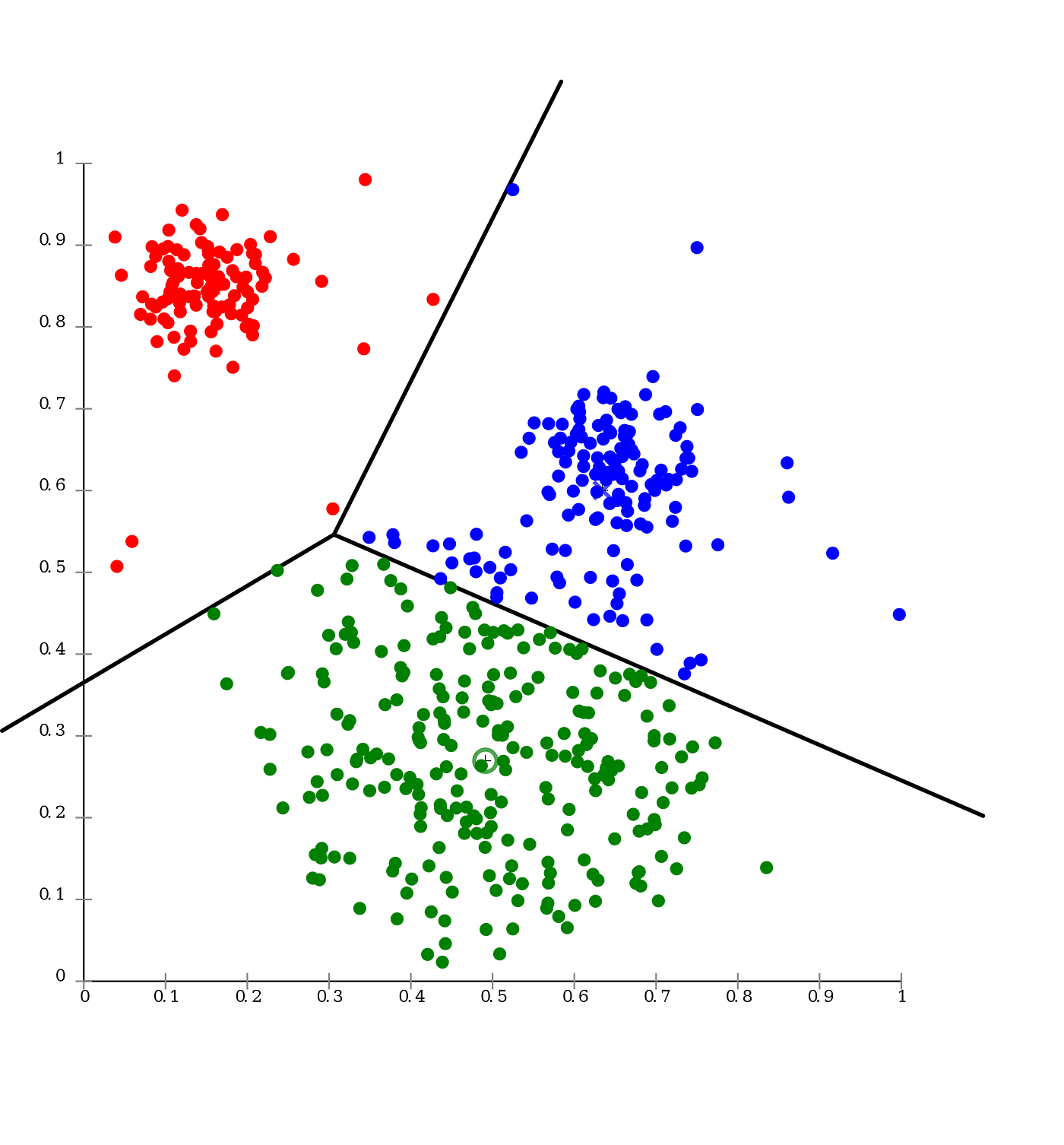
3-Yard-means
Say you accept a lot of information points (measurements for fruits) and you want to split them into ii groups apple and pears. K-means clustering is a clustering algorithm used to automatically divide a large grouping into smaller groups.
The name comes because you lot choose K groups in our example K=ii. You take the boilerplate of these groups to improve the accurateness of the grouping (average is equal to mean, and you do this several times). The cluster is but some other name for a group.
Permit's say you have 13 data points, which in actuality are 7 apples and half-dozen pears, (just you don't know this) and you want to split them into two groups. For this instance allow's presume that all the pear are larger than all the apples. You select ii random data points as a starting position. And then, you compare these points to all the other points and find out which starting position is closest. This is your first pass at clustering and this is the slowest part.
Yous have your initial groups, merely because you chose randomly, you are probably inaccurate. Say you got six apples and ane pear in one group, and 2 apples and four pears in the other. And then, you have the average of all the points in 1 group to use every bit a new starting point for that group and exercise the aforementioned for the other group. Then you do the clustering once more to get new groups.
Success! Considering the average is closer to the majority of each cluster, on the second go around y'all get all apples in one group and all pears in the other. How do you know y'all're done? You do the average and y'all are performing grouping over again and see if whatsoever points changed the groups. None did, so you're finished. Otherwise, you'd go again.
4-KNN
Direct away, the two seek to accomplish different goals. K-nearest neighbors is a nomenclature algorithm, which is a subset of supervised learning. K-means is a clustering algorithm, which is a subset of unsupervised learning.
If nosotros have a dataset of football game players, their positions, and their measurements, and we want to assign positions to football players in a new dataset where we have measurements but no positions, we might use K-nearest neighbors.
On the other paw, if nosotros accept a dataset of football players who need to be grouped into K distinct groups based off of similarity, we might use 1000-means. Correspondingly, the Grand in each example also mean different things!
In 1000-nearest neighbors, the K represents the number of neighbors who take a vote in determining a new player'south position. Check the example where K=v. If we have a new football actor who needs a position, nosotros take the five football players in our dataset with measurements closest to our new football player, and we have them vote on the position that we should assign the new player.
In K-means the K means the number of clusters nosotros want to have in the end. If K= 7, I will have seven clusters, or singled-out groups, of football players after I run the algorithm on my dataset. In the end, two different algorithms with 2 very different purpose, but the fact that they both use K can be very disruptive.

5-Support Vector Machines
SVM uses hyperplanes (straight things) to separate two differently labeled points (X's and O's). Sometimes the points tin can't be separated by straight things, then information technology needs to map them to a higher dimensional infinite (using kernels!) where they tin can be carve up by straight things (hyperplanes!). This looks like a curvy line on the original space, even though it is actually a straight thing in a much higher dimensional space!

vi-Random Forest
Let'due south say we want to know when to invest in Procter & Gamble and then we have 3 choices buy, sell and concur based on several information from the past month like open price, close cost, modify in the price and volume
Imagine you have a lot of entries, 900 points of data.
We want to build a conclusion tree to decide the best strategy, for example, if in that location is a change in the cost of the stock more than than x percent college than the day before with high book we purchase this stock. But nosotros don't know which features to use, we have a lot.
And then we take a random gear up of measures and a random sample of our training set and nosotros build a determination tree. Then we do the aforementioned many times using a different random set of measurements and a random sample of information each fourth dimension. At the end we have many decision trees, we use each of them to forecast the price and then make up one's mind the concluding prediction based on a simple majority.
7-Neural networks
A neural network is a form of artificial intelligence. The basic thought behind a neural network is to simulate lots of densely interconnected brain cells inside a figurer then it can get it to learn things, recognize patterns, and make decisions in a human being-like way. The amazing thing about a neural network is that it doesn't take to plan it to learn explicitly: information technology learns all by itself, but like a brain!
On one hand of the neural network, there are the inputs. This could exist a picture, data from a drone, or the land of a Go board. On the other manus, there are the outputs of what the neural network wants to do. In betwixt, there are nodes and connections between those. The forcefulness of the connections determines what output is called for based on the inputs.
Check our costless course AWS with python on Udemy.
Thank you for reading. If y'all loved this commodity, feel free to striking that follow push then we can stay in bear upon.

Source: https://towardsdatascience.com/do-you-know-how-to-choose-the-right-machine-learning-algorithm-among-7-different-types-295d0b0c7f60
Posted by: hesslockonamind.blogspot.com
0 Response to "How To Choose A Machine Learning Algorithm"
Post a Comment