

How To Design Deep Learning Architecture
By Lavanya Shukla, Weights and Biases.
Training neural networks can exist very disruptive!
What'south a good learning rate? How many hidden layers should your network accept? Is dropout really useful? Why are your gradients vanishing?
In this postal service, we'll peel the curtain backside some of the more disruptive aspects of neural nets, and help you lot make smart decisions about your neural network architecture.
I highly recommend forking this kernel and playing with the different building blocks to hone your intuition.
If y'all take any questions, feel free to message me. Good luck!
one. Bones Neural Network Construction
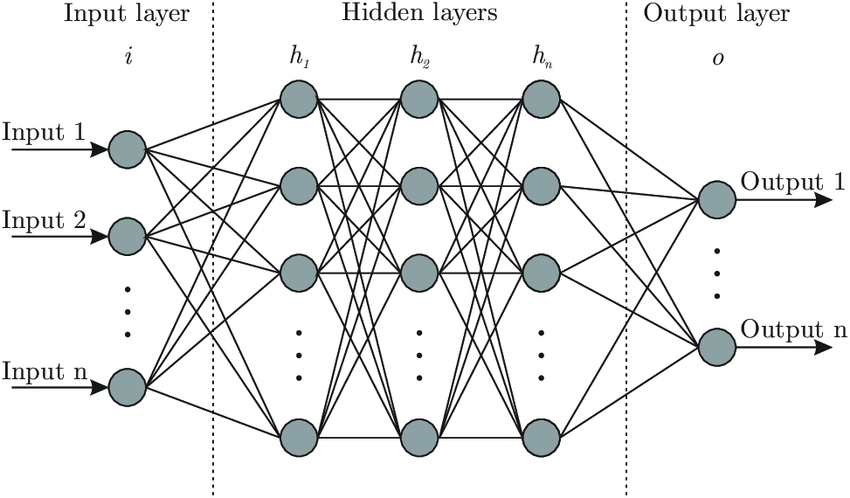
Inp ut neurons
- This is the number of features your neural network uses to make its predictions.
- The input vector needs ane input neuron per feature. For tabular information, this is the number of relevant features in your dataset. You desire to carefully select these features and remove whatever that may contain patterns that won't generalize beyond the training set (and cause overfitting). For images, this is the dimensions of your paradigm (28*28=784 in example of MNIST).

Output neurons
- This is the number of predictions you want to brand.
- Regression:For regression tasks, this tin can be one value (e.m., housing cost). For multi-variate regression, it is one neuron per predicted value (eastward.yard., for bounding boxes it can exist iv neurons — one each for bounding box height, width, x-coordinate, y-coordinate).
- Classification:For binary classification (spam-not spam), we utilise one output neuron per positive class, wherein the output represents the probability of the positive class. For multi-grade classification (east.g., in object detection where an instance can be classified as a car, a domestic dog, a house, etc.), we have one output neuron per class and use the softmax activation function on the output layer to ensure the concluding probabilities sum to one.
Hidden Layers and Neurons per Subconscious Layers
- The number of hidden layers is highly dependent on the problem and the compages of your neural network. You lot're essentially trying to Goldilocks your fashion into the perfect neural network architecture — non too large, not besides small, only right.
- Generally, 1–five hidden layers will serve you well for most bug. When working with image or speech data, you'd want your network to have dozens-hundreds of layers, not all of which might exist fully connected. For these use cases, there are pre-trained models (YOLO, ResNet, VGG) that let y'all to employ big parts of their networks, and train your model on top of these networks to larn just the higher-order features. In this case, your model will still take merely a few layers to train.
- In general, using the same number of neurons for all hidden layers will suffice. For some datasets, having a large first layer and following it up with smaller layers will lead to improve operation equally the first layer can learn a lot of lower-level features that can feed into a few higher-social club features in the subsequent layers.
- Unremarkably, you will go more of a performance boost from adding more layers than adding more neurons in each layer.
- I'd recommend starting with i–5 layers and 1–100 neurons and slowly adding more than layers and neurons until y'all beginning overfitting. You can runway your loss and accuracy within your Weights and Biases dashboard to see which hidden layers + hidden neurons combo leads to the all-time loss.
- Something to go on in mind with choosing a smaller number of layers/neurons is that if this number is likewise small, your network will not exist able to learn the underlying patterns in your information and thus exist useless. An approach to counteract this is to start with a huge number of hidden layers + hidden neurons then use dropout and early stopping to allow the neural network size itself downwards for you lot. Again, I'd recommend trying a few combinations and track the performance in your Weights and Biases dashboard to determine the perfect network size for your problem.
- Andrej Karpathy also recommends the overfit then regularize approach — "commencement get a model big enough that it can overfit (i.e., focus on training loss) and then regularize it accordingly (give upward some training loss to improve the validation loss)."
Loss function
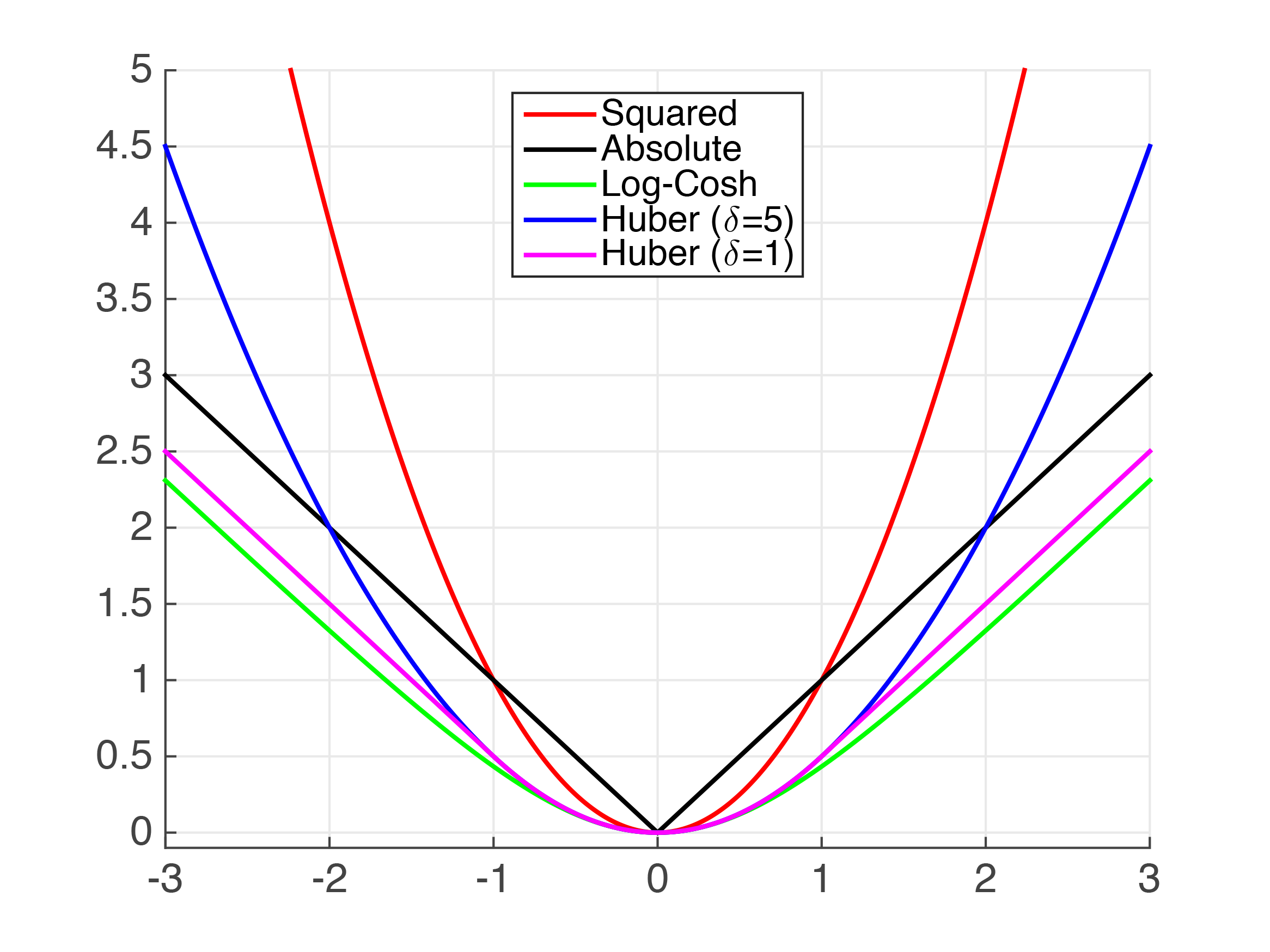
- Regression:Hateful squared error is the nigh common loss office to optimize for unless there are a pregnant number of outliers. In this case, use mean absolute mistake orHuber loss.
- Classification: Cantankerous-entropy will serve yous well in most cases.
Batch Size
- Big batch sizes can be great because they can harness the power of GPUs to process more training instances per time. OpenAI has found larger batch sizes (of tens of thousands for image-classification and language modeling, and of millions in the case of RL agents) serve well for scaling and parallelizability.
- There'due south a case to be made for smaller batch sizes, as well, however. According to this paper by Masters and Luschi, the advantage gained from increased parallelism from running large batches is offset by the increased performance generalization and smaller memory footprint achieved by smaller batches. They bear witness that increased batch sizes reduce the acceptable range of learning rates that provide stable convergence. Their takeaway is that smaller is, in-fact, amend; and that the best performance is obtained past mini-batch sizes between 2 and 32.
- If you're not operating at massive scales, I would recommend starting with lower batch sizes and slowly increasing the size and monitoring operation in your Weights and Biases dashboard to make up one's mind the all-time fit.
Number of epochs
- I'd recommend starting with a big number of epochs and use Early Stopping (run into department four. Vanishing + Exploding Gradients) to halt training when operation stops improving.
Scaling your features
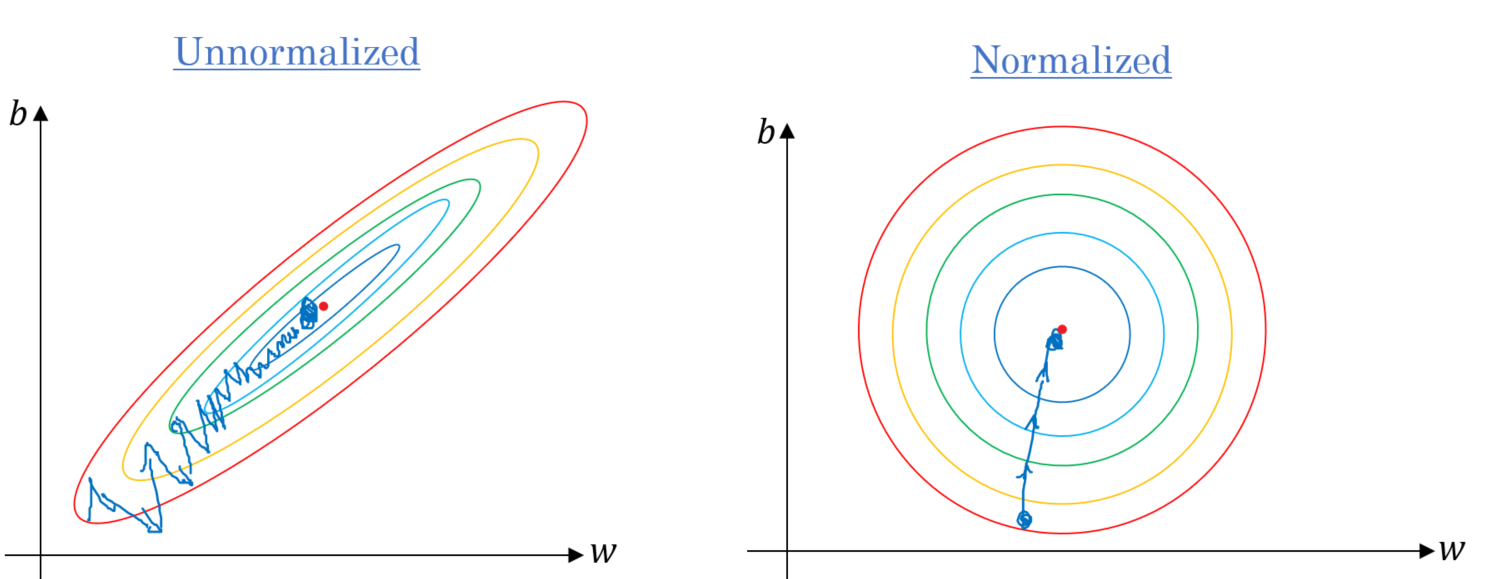
- A quick note: Make sure all your features have a similar calibration before using them as inputs to your neural network. This ensures faster convergence. When your features have different scales (east.thou., salaries in thousands and years of experience in tens), the price function will wait like the elongated bowl on the left. This means your optimization algorithm volition take a long time to traverse the valley compared to using normalized features (on the right).
2. Learning Rate
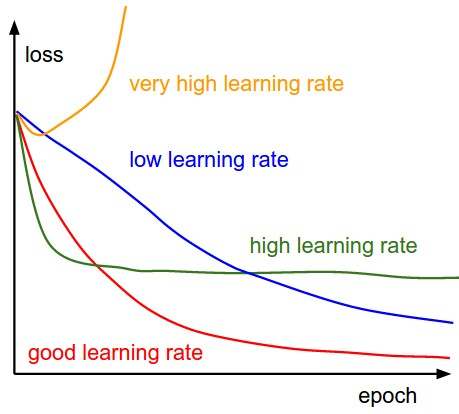
- Picking the learning rate is very important, and y'all desire to make sure y'all get this right! Ideally, yous desire to re-tweak the learning rate when you tweak the other hyper-parameters of your network.
- To find the all-time learning charge per unit, start with a very low value (10^-6) and slowly multiply it by a constant until information technology reaches a very high value (eastward.one thousand., 10). Measure your model functioning (vs. the log of your learning rate) in your Weights and Biases dashboard to determine which rate served you well for your trouble. Y'all can then retrain your model using this optimal learning rate.
- The best learning rate is usually half of the learning rate that causes the model to diverge. Feel gratis to set unlike values for learn_rate in the accompanying code and seeing how it affects model functioning to develop your intuition around learning rates.
- I'd also recommend using the Learning Rate finder method proposed by Leslie Smith. Information technology an fantabulous way to find a proficient learning rate for most gradient optimizers (almost variants of SGD) and works with most network architectures.
- Also, see the section on learning rate scheduling below.
3. Momentum
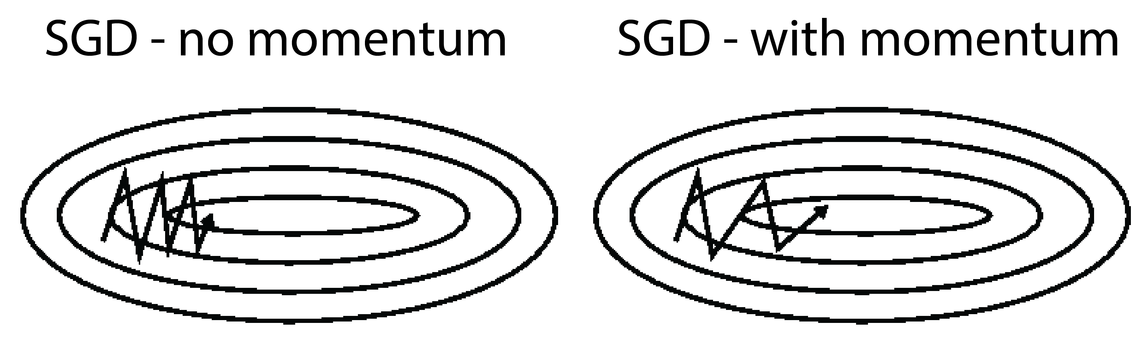
- Slope Descent takes tiny, consistent steps towards the local minima and when the gradients are tiny it can take a lot of time to converge. Momentum, on the other hand, takes into account the previous gradients, and accelerates convergence by pushing over valleys faster and avoiding local minima.
- In general, y'all want your momentum value to be very close to one. 0.9 is a practiced place to kickoff for smaller datasets, and y'all want to movement progressively closer to one (0.999) the larger your dataset gets. (Setting nesterov=True lets momentum take into account the gradient of the cost office a few steps ahead of the electric current point, which makes it slightly more accurate and faster.)
4. Vanishing + Exploding Gradients
- Just like people, not all neural network layers acquire at the same speed. So when the backprop algorithm propagates the error gradient from the output layer to the first layers, the gradients get smaller and smaller until they're almost negligible when they reach the first layers. This means the weights of the start layers aren't updated significantly at each step.
- This is the problem of vanishing gradients. (A like trouble of exploding gradients occurs when the gradients for certain layers get progressively larger, leading to massive weight updates for some layers as opposed to the others.)
- At that place are a few ways to annul vanishing gradients. Let's accept a look at them at present!
Activation functions
Subconscious Layer Activation
In full general, the operation from using different activation functions improves in this order (from lowest→highest performing): logistic → tanh → ReLU → Leaky ReLU → ELU → SELU.
ReLU is the most popular activation function and if you don't want to tweak your activation function, ReLU is a great place to start. But, continue in mind ReLU is becoming increasingly less effective than ELU or GELU.
If y'all're feeling more than audacious, you can effort the post-obit:
- to combat neural network overfitting: RReLU
- reduce latency at runtime: leaky ReLU
- for massive training sets: PReLU
- for fast inference times: leaky ReLU
- if your network doesn't self-normalize: ELU
- for an overall robust activation function: SELU
Every bit e'er, don't exist afraid to experiment with a few different activation functions, and plough to your Weights and Biases dashboard to help you pick the one that works best for you!
This is an excellent paper that dives deeper into the comparison of various activation functions for neural networks.
Output Layer Activation
Regression: Regression problems don't require activation functions for their output neurons considering we want the output to take on any value. In cases where we want out values to be divisional into a sure range, we can apply tanh for -1→one values and logistic function for 0→ane values. In cases where we're only looking for positive output, we tin can use softplus activation.
Nomenclature: Utilize the sigmoid activation function for binary classification to ensure the output is betwixt 0 and one. Use softmax for multi-class nomenclature to ensure the output probabilities add up to 1.
Weight initialization method
- The right weight initialization method can speed upwards time-to-convergence considerably. The choice of your initialization method depends on your activation function. Some things to try:
- When using ReLU or leaky RELU, employ He initialization
- When using SELU or ELU, apply LeCun initialization
- When using softmax, logistic, or tanh, utilize Glorot initialization
- Most initialization methods come in uniform and normal distribution flavors.
BatchNorm
- BatchNorm merely learns the optimal means and scales of each layer'southward inputs. Information technology does and then past zero-centering and normalizing its input vectors, then scaling and shifting them. Information technology as well acts like a regularizer, which ways we don't demand dropout or L2 reg.
- Using BatchNorm lets united states use larger learning rates (which result in faster convergence) and lead to huge improvements in most neural networks by reducing the vanishing gradients problem. The simply downside is that it slightly increases grooming times considering of the extra computations required at each layer.
Gradient Clipping
- A great way to reduce gradients from exploding, especially when grooming RNNs, is to simply clip them when they exceed a certain value. I'd recommend trying clipnorm instead of clipvalue, which allows you to go along the direction of your gradient vector consistent. Clipnorm contains any gradients who'southward l2 norm is greater than a certain threshold.
- Try a few unlike threshold values to find one that works all-time for you.
Early Stopping
- Early Stopping lets you live it upward past training a model with more hidden layers, hidden neurons and for more epochs than you demand, and just stopping training when performance stops improving consecutively for north epochs. It likewise saves the best performing model for you. You can enable Early Stopping past setting up a callback when you lot fit your model and setting save_best_only=True.
5. Dropout
- Dropout is a fantastic regularization technique that gives you a massive performance boost (~ii% for state-of-the-art models) for how simple the technique actually is. All dropout does is randomly turn off a pct of neurons at each layer, at each grooming step. This makes the network more robust because information technology tin can't rely on any particular set of input neurons for making predictions. The cognition is distributed amongst the whole network. Effectually 2^n (where northward is the number of neurons in the architecture) slightly-unique neural networks are generated during the training process and ensembled together to make predictions.
- A good dropout rate is betwixt 0.i to 0.5, 0.3 for RNNs, and 0.5 for CNNs. Use larger rates for bigger layers. Increasing the dropout charge per unit decreases overfitting, and decreasing the rate is helpful to combat under-fitting.
- You desire to experiment with different rates of dropout values in earlier layers of your network and cheque your Weights and Biases dashboard to pick the best performing i. Y'all definitely don't want to use dropout in the output layers.
- Read this paper before using Dropout in conjunction with BatchNorm.
- In this kernel, I used AlphaDropout, a flavor of the vanilla dropout that works well with SELU activation functions by preserving the input's mean and standard deviations.
half dozen. Optimizers
- Gradient Descent isn't the only optimizer game in town! In that location are a few different ones to choose from. This post does a good chore of describing some of the optimizers you can choose from.
- My general advice is to use Stochastic Gradient Descent if yous intendance deeply almost the quality of convergence and if time is not of the essence.
- If you intendance nearly fourth dimension-to-convergence and a point close to optimal convergence will suffice, experiment with Adam, Nadam, RMSProp, and Adamax optimizers. Your Weights and Biases dashboard will guide you to the optimizer that works all-time for you!
- Adam/Nadam are usually good starting points and tend to be quite forgiving to bad learning rates and other non-optimal hyperparameters.
- According to Andrej Karpathy, "a well-tuned SGD will virtually always slightly outperform Adam" in the example of ConvNets.
- In this kernel, I got the best performance from Nadam, which is just your regular Adam optimizer with the Nesterov trick, and thus converges faster than Adam.
7. Learning Charge per unit Scheduling
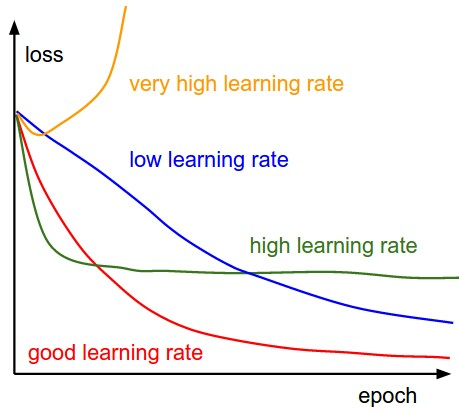
- We talked about the importance of a good learning rate already — we don't desire it to be too high, lest the cost function dance effectually the optimum value and diverge. Nosotros too don't want it to exist too low because that means convergence will take a very long fourth dimension.
- Babysitting the learning rate can exist tough because both higher and lower learning rates accept their advantages. The great news is that we don't have to commit to one learning rate! With learning rate scheduling we can start with higher rates to move faster through gradient slopes, and slow it downwards when we reach a gradient valley in the hyper-parameter space, which requires taking smaller steps.
- At that place are many means to schedule learning rates including decreasing the learning rate exponentially, or by using a pace function, or tweaking it when the performance starts dropping or using 1cycle scheduling. In this kernel, I show y'all how to employ the ReduceLROnPlateau callback to reduce the learning rate by a constant factor whenever the performance drops for n epochs.
- I would highly recommend also trying out 1cycle scheduling.
- Use a constant learning rate until you lot've trained all other hyper-parameters. And implement learning rate disuse scheduling at the cease.
- As with most things, I'd recommend running a few different experiments with different scheduling strategies and using your Weights and Biases dashboard to option the one that leads to the all-time model.
A Few More Things
- Endeavour EfficientNets to scale your network in an optimal way.
- Read this paper for an overview of some additional learning rates, batch sizes, momentum, and weight disuse techniques.
- And this one on Stochastic Weight Averaging (SWA). It shows that better generalization can exist achieved past averaging multiple points along the SGD's trajectory, with a cyclical or constant learning rate.
- Read Andrej Karpathy's excellent guide on getting the most juice out of your neural networks.
Results
We've explored a lot of different facets of neural networks in this post!
Nosotros've looked at how to set up upward a bones neural network (including choosing the number of hidden layers, hidden neurons, batch sizes, etc.)
We've learned well-nigh the role momentum and learning rates play in influencing model performance.
And finally, we've explored the problem of vanishing gradients and how to tackle information technology using non-saturating activation functions, BatchNorm, better weight initialization techniques and early stopping.
You can compare the accuracy and loss performances for the various techniques we tried in 1 single chart, by visiting your Weights and Biases dashboard.
Neural networks are powerful beasts that give you a lot of levers to tweak to become the best performance for the problems you lot're trying to solve! The sheer size of customizations that they offer tin can be overwhelming to even seasoned practitioners. Tools like Weights and Biases are your all-time friends in navigating the state of the hyper-parameters, trying different experiments and picking the most powerful models.
I hope this guide will serve as a good starting point in your adventures. Adept luck! I highly recommend forking this kernel and playing with the different building blocks to hone your intuition.
Bio: Lavanya is a machine learning engineer at Weights and Biases. She began working on AI ten years agone when she founded ACM SIGAI at Purdue Academy as a sophomore. In a past life, she taught herself to code at age ten, and built her beginning startup at 14. She's driven by a deep desire to understand the universe around us amend past using machine learning.
Related:
- Introduction to Bogus Neural Networks
- five Beginner Friendly Steps to Learn Machine Learning and Data Scientific discipline with Python
- Build an Artificial Neural Network From Scratch: Part ane

How To Design Deep Learning Architecture,
Source: https://www.kdnuggets.com/2019/11/designing-neural-networks.html
Posted by: hesslockonamind.blogspot.com
0 Response to "How To Design Deep Learning Architecture"
Post a Comment